
Sticky Session
1. 개요
최근 외부 시스템과 로그인 처리를 연동해야할 일이 있었는데, 해당 시스템은 SAML기반 인증 방식 을 사용하고 있었다.
카카오, 네이버, 구글등은 로그인을 Oauth 2.0 기반의 사용자 인증 기능을 제공하는데, 개인적으로는 SAML 인증 방식은 처음 접해봤다.
가이드 문서가 잘 되어 있어서 개발환경 / 테스트 환경에서는 문제없이 개발 및 테스트를 진행했다. 그러나 라이브 서버에 배포했을때 문제가 발생했다. 짧지 않은 시간동안 끙끙 앓다가 어느순간 머리를 스치듯 한 생각이 지나갔다.
세션 인증 방식을 사용하고 있어 요청 / 응답하는 서버가 다르면 에러가 발생한다? 라는 생각이다. 실제로 확인해보니, A 인스턴스가 요청한 인증을 B 인스턴스가 받아서 처리하면 에러가 발생한다.
그렇다면 만약 최초 접속을 A 인스턴스로 하였다면 그 이후의 모든 요청은 A 인스턴스로 라우팅 될 수 있도록 조치가 필요하다. 이때 필요한 것이 Sticky Session 기능이다. nginx로 치면 ip_hash와 비슷하다고 볼 수 있겠다.
라이브 서버는 Application Load Balancer를 사용하고 있는데 다행히 설정 하나로 Sticky Session 설정이 가능하다.
2. 왜 발생하지?
개인적으로 기억을 정리하기 위한 문단입니다. 궁금하지 않으신 분들은 다음 문단으로 넘어가 주세요.
근데 뭔가 이상하다. SAML 토큰에는 일반적으로 서명(signature)이 포함되어 있어 토큰의 무결성을 보장한다. 따라서 요청 서버와 응답 서버가 다르더라도 서명 검증을 통해 SAML 토큰의 유효성을 확인할 수 있다. (확실하지 않음…)
물론 이를 위해선 요청 서버와 인증 서버간 적절한 키 or 인증서 공유가 이루어져야 한다. 나의 경우 이러한 키를 전달받아 적용한 상태였다.
그런데도 에러가 발생해 라이브러리 코드를 까봤다. 까보니 이유를 찾을수 있었다.
- 인증 요청시 message 생성후 Map 형태의 LocalStorage class에 데이터 저장후 인증 요청
- 인증 성공후 인증 정보 파싱시 LocalStorage class에서 데이터 검색
- 인스턴스가 다르니 당연히 각각의 인스턴스에 LocalStorage가 존재함
- A 인스턴스에 저장된 정보를 B 인스턴스에서 찾고자 하니 에러 발생
이 라이브러리는 2010년대 초반에 만들어진듯 한데, 그때는 서버를 이중화로 구성하지 않았나? 잘 모르겠다… 어쨌거나 명확한 문제를 찾아서 속이 시원했다.
3. AWS 에서 Sticky Session 설정하기
위에서 말했다시피 현재 서비스는 Application Load Balancer을 사용하고 있었고, 다행히 간단한 설정으로 Sticky Session을 설정할 수 있었다.
Sticky Session은 로브밸런서가 아닌 대상 그룹 에서 확인할 수 있다.
대상 그룹 -> 타겟 -> 속성 -> 편집 순으로 이동하자.

편집 페이지에 들어왔으면 대상 선택 구성 항목을 찾을 수 있다.
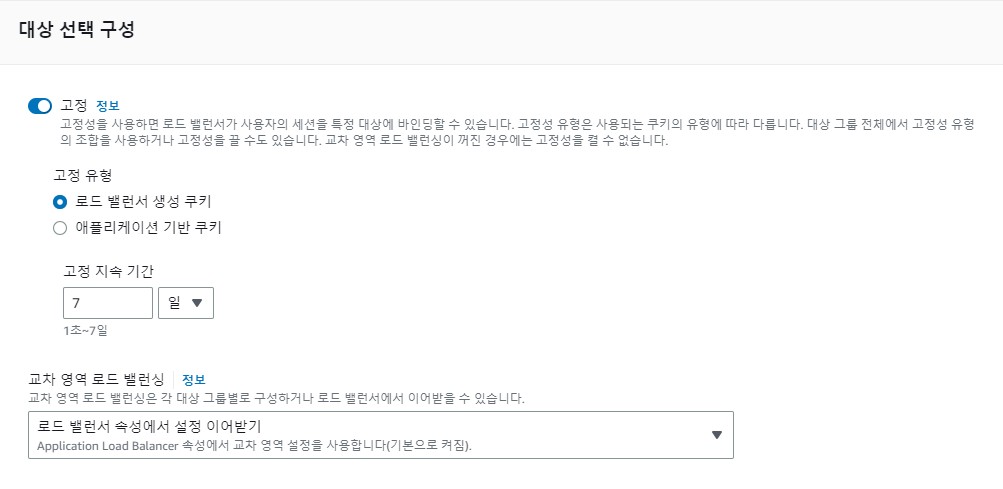
옵션을 활성화 하고 고정 유형을 로드 밸런서 생성 쿠키로 선택한다. 애플리케이션 기반 쿠키를 선택한다면 애플리케이션 레벨에서 처리를 해줘야 하기 때문에 귀찮다.
적당한 고정 지속 시간을 선택한다. 예를들어 1일로 지정했다면 오늘 10시에 사용자의 요청이 로드밸런서를 통해 A 인스턴스로 흘러 들어갔다면 내일 10시까지는 해당 사용자의 모든 요청은 A 인스턴스로 흘러 들어가게 된다.
저장하면 완료다. 정말 간단하게 설정할 수 있다.

위와같이 요청에 AWSALB, AWSALBCORS 라는 이름의 쿠키가 있다면 성공이다. 가장 확실한 방법은 어떤 인스턴스인지 확인할 수 있는 방법을 만들고 배포하여 확인해보는 것이다.
4. 결론
Sticky Session은 특정 클라이언트의 요청을 항상 동일한 서버로 보내기 때문에 일부 서버에 부하가 집중될 수 밖에 없다.
이를 사용하는 도중 서버에 장애가 발생하거나 다운되면 해당 클라이언트의 요청은 다른 서버로 전달되지 못하고 서비스 중단 현상이 발생할 수 있어 전체 시스템의 성능 저하를 야기할 수 있다.
그러나 나로서는 급한 상황이라 선택지가 없었고, 어쩔수 없이 적용하게 되었다.
아예 별도의 도메인과 별도의 인스턴스를 띄워 장애가 발생하더라도 기존 시스템에 영향을 주지 않도록 하고 싶었지만 문제는 돈이지…
서버 비용을 아예 신경 안쓸순 없겠지만 시스템의 안정성을 위해서라도 분리 할껀 하고 돈 낼껀 내주면 좋겠다. (이직하자)