
반복자 패턴
반복자 패턴은 객체지향 프로그래밍에서 반복자를 사용하여 컨테이너를 가로지르며 컨테이너의 요소들에 접근하는 디자인 패턴입니다… 라고 위키에는 나와 있습니다만 한번에 이해되지는 않습니다.
1
2
3
4
5
String[] stringArray = {"월", "화", "수", "목", "금", "토", "일"};
for (int i = 0; i < stringArray.length; i++) {
System.out.println(stringArray[i]);
}
위와같은 코드가 있을 때 컨테이너는 stringArray 배열을 지칭하고 반복자는 변수 i를 지칭합니다. 여기서 중요한것은 변수 i 인데요, i는 다음과 같은 기능을 합니다.
- 현재 가로지르고 있는 배열의 위치를 나타낸다.
- 값을 증가시켜 컨테이너의 모든 요소들에 접근할수 있도록 해준다.
위 코드에서 i가 하고 있는 기능을 추상화 하여 일반화 한 것을 반복자 패턴이라고 합니다. 더 쉽게 풀어쓰자면 각기 다른 자료구조(컬렉션)가 있다고 가정했을 때 이 각각의 자료구조에 접근할 수 있는 방법을 모두 알 필요 없이 반복기능만 통일하여 일반화 한 패턴 정도로 이해하시면 될 것 같습니다.
반복자 패턴에서 중요하게 여겨지는 원칙은 SRP(단일 책임 원칙) 입니다. 단일 책임 원칙이란 클래스는 하나의 책임만 가져야 하며, 클래스를 변경하는 이유도 한개여야 함을 의미합니다.
구조
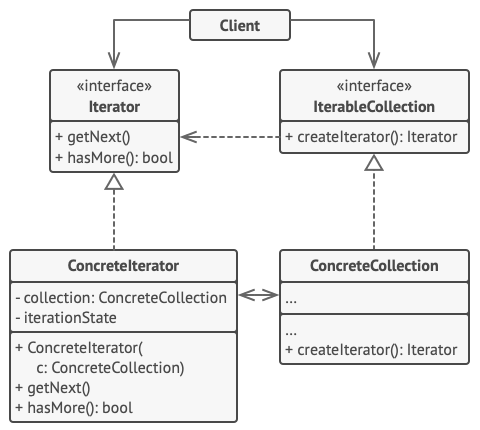
- 반복자 인터페이스는 컬렉션 순회에 필요한 적업(다음 요소 가져오기, 현재 위치 검색, 반복 재시작 등) 을 선언합니다.
- 반복자 인터페이스의 구현체는 컬렉션 순회를 위한 알고리즘을 구현합니다. 반복자 객체는 자체적으로 진행중인 순회를 추적해야 합니다.
- 컬렉션 인터페이스는 컬렉션과 호환되는 반복자를 얻기 위해 하나 이상의 메소드를 선언합니다.
- 컬렉션 인터페이스의 구현체는 클라이언트가 요청할 때마다 특정 구현체 클래스의 새로운 인스턴스를 반환합니다.
- 클라이언트는 인터페이스를 통해 반복자, 컬렉션을 사용할 수 있습니다. 이렇게 하면 클라이언트가 구현 클래스와 결합되지 않으므로 동일한 클라이언트 코드로 다양한 반복자와 컬렉션을 사용할 수 있습니다.
적용 가능한 경우
- 컬렉션이 내부적으로 복잡한 데이터 가지고 있지만 그 복잡성을 클라이언트로부터 숨기고 싶을 때 반복자 패턴을 사용합니다.
- 반복자는 복잡한 데이터 작업에 대한 세부 정보를 캡슐화하여 클라이언트에 컬렉션 요소에 액세스하는 몇 가지 간단한 방법을 제공합니다. 이를 통해 클라이언트는 컬렉션의 복잡성을 알 수 없으므로 부주의하거나 악의작인 작업을 수행할 수 없습니다.
- 앱 전체에서 순회 코드의 중복을 줄이고자 할 때 반복자 패턴을 사용합니다.
- 클라이언트 코드가 다른 데이터 구조를 순회하기를 원하거나 이러한 구조의 유형을 미리 알 수 없는 경우 반복자 패턴을 사용합니다.
장단점
장점
- 크기가 큰 순회 알고리즘을 별도의 클래스로 추출하여 클라이언트 코드와 컬렉션을 정리함으로 인해 단일 책임 원칙을 만족할 수 있습니다.
- 새로운 유형의 컬렉션 및 반복자를 구현하고 기존의 코드는 수정하지 않음으로써 개방/폐쇄 원칙을 만족할 수 있습니다.
- 각각의 반복자 객체는 그들만의 고유한 반복 상태가 포함되어 있기 때문에 동일한 컬렉션을 병렬로 반복할 수 있습니다.
- 위와 같은 이유로 반복을 지연시킬 수 있고 필요할 때 계속할 수 있습니다.
단점
- 앱이 간단한 컬렉션 만으로도 동작하는 경우 패턴을 적용하는 것이 오히려 지나칠 수 있습니다.
- 반복자를 사용하는 것은 일부 특수 컬렉션의 요소를 직접 탐색하는 것 보다 덜 효율적일 수 있습니다.
예제
사용자 컬렉션의 정보를 모두 가져와 콘솔창에 보여주는 프로그램을 하나 만들어 보겠습니다.
우리가 확인할 유저 객체는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
public class User {
private String name;
private int age;
private String loginId;
public User(String name, int age, String loginId) {
this.name = name;
this.age = age;
this.loginId = loginId;
}
public String getName() {
return name;
}
public int getAge() {
return age;
}
public String getLoginId() {
return loginId;
}
}
그 후 두개의 인터페이스를 만들겠습니다.
1
2
3
4
5
6
7
8
public interface Iterator {
boolean hasNext();
Object next();
}
public interface Container {
Iterator getIterator();
}
다음은 각각의 인터페이스를 구현하는 구현체를 만들겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
public class UserIterator implements Iterator {
private List<User> userList;
int currentPosition = 0;
public UserIterator(List<User> userList) {
this.userList = userList;
}
@Override
public boolean hasNext() {
return currentPosition < userList.size();
}
@Override
public Object next() {
if (hasNext()) {
return userList.get(currentPosition ++);
}
return null;
}
}
public class UserRepository implements Container {
private List<User> userList;
public UserRepository(List<User> userList) {
this.userList = userList;
}
@Override
public Iterator getIterator() {
return new UserIterator(this.userList);
}
}
마지막으로 클라이언트 코드입니다. 이 코드는 모든 사용자의 정보를 출력합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
public class Client {
public static void main(String[] args) {
UserRepository userRepository = new UserRepository(getTestUserList());
for (Iterator it = userRepository.getIterator(); it.hasNext();) {
System.out.println("===========================================");
User user = (User) it.next();
System.out.println(user.getName());
System.out.println(user.getAge());
System.out.println(user.getLoginId());
System.out.println("===========================================");
}
}
private static List<User> getTestUserList() {
return new ArrayList<>(
Arrays.asList(
new User("홍길동", 20, "gildong"),
new User("이순신", 50, "sunshin"),
new User("김첨지", 43, "chumji"),
new User("신사임당", 20, "imgentleman")
)
);
}
}
모든 사용자의 정보가 콘솔에 출력되면 성공입니다.
일반적인 반복문과의 차이
만약 위 예제를 Iterator를 사용하지 않고 foreach loop를 사용하면 어떻게 될까요?
1
2
3
4
5
6
7
8
9
10
11
public static void main(String[] args) {
List<User> userList = getTestUserList();
for (User user : userList) {
System.out.println("===========================================");
System.out.println(user.getName());
System.out.println(user.getAge());
System.out.println(user.getLoginId());
System.out.println("===========================================");
}
}
동작 자체는 Iterator를 사용하였을 때와 동일할 것이고 코드 양도 줄었습니다. 하지만 Iterator는 foreach loop가 할 수 없는 일들을 할 수 있습니다.
예를들어 요소 제거 를 할 수 있습니다. 일반적인 foreach 문으로 요소를 제거할 경우 ConcurrentModificationException 예외가 발생하는데 반해, Iterator를 이용하여 요소를 제거할 경우 안전하게 요소를 제거할 수 있습니다. 자바 8 이상의 버전을 사용한다면 새로운 메소드(removeIf), Stream API(filter) 를 사용해도 안전하게 요소를 제거할 수 있습니다.
이러한 일이 발생하는 이유는 일반 for, foreach 문의 경우 반복자가 hasNext(), next() 에 대해 반환할 내용을 모르기 때문입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
List<User> userList = getTestUserList();
// OK
for (Iterator<User> iterator = userList.iterator(); iterator.hasNext();) {
User user = iterator.next();
if ("gildong".equals(user.getLoginId())) {
iterator.remove();
}
}
// ConcurrentModificationException Error
for (User user : userList) {
if ("gildong".equals(user.getLoginId())) {
userList.remove(user);
}
}
// OK
userList.removeIf(user -> "gildong".equals(user.getLoginId()));
결론
반복자 패턴을 사용하면 구현 클래스 내부에서 어떤 식으로 일이 처리되는지 알 필요 없이(자료구조와 관계없이) 컬렉션 내부의 모든 항목에 접근할 수 있습니다. 다만 Iterator를 사용하는 경우 for loop를 사용하는 것 보다 성능이 떨어질 수 있으니 주의가 필요합니다.
참조
https://refactoring.guru/design-patterns/iterator https://stackoverflow.com/a/22268270/13160032