
JPA 캐시
데이터베이스에 접근하는 비용은 매우 비쌉니다. 실제 운영하는 서비스라면 DB가 같은 시스템 안에 존재하는 일이 없기 때문에 네트워크 비용까지 발생합니다. 결과값을 뻔히 알 수 있는 쿼리에 대해 이런 값비싼 작업을 수행한다면 어플리케이션의 성능은 낮아질 것입니다.
하이버네이트를 포함한 JPA 구현체들은 캐시를 지원합니다. 하이버네이트의 캐시는 어플리케이션과 데이터베이스 사이에 중간다리 계층 역할을 하며, 데이터베이스를 직접 호출하는 대신 서버 메모리에서 결과값을 반환하므로 데이터를 얻는데 걸리는 시간을 줄여줄뿐 아니라 어플리케이션의 성능까지 높일 수 있습니다.
1차 캐시
1차캐시부터 살펴보겠습니다. 1차캐시는 영속성 컨텍스트 내부에 엔티티를 보관하는 장소를 의미합니다. 1차캐시는 하이버네이트에서 기본적으로 사용되도록 설정되어 있습니다. 1차캐시는 트랜잭션을 시작하고 종료할 때까지만 존재합니다.
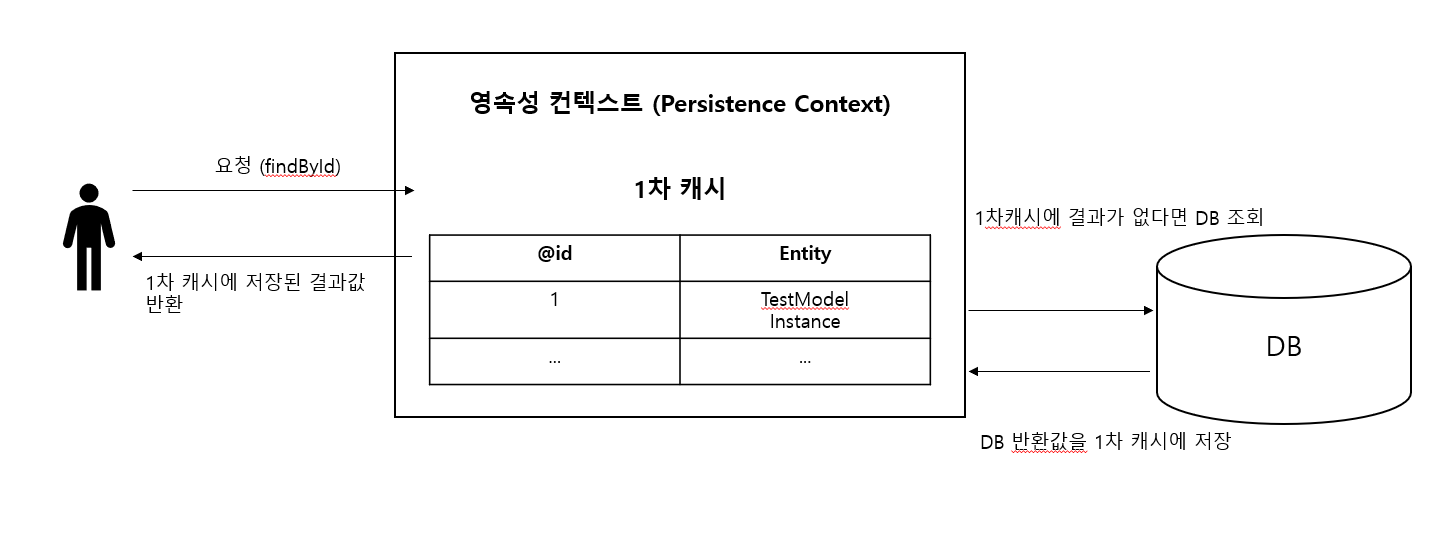 플로우를 간단히 도식화해보면 위와 같습니다. 요청이 오면 1차 캐시에서 요청과 일치하는 엔티티가 있는지 확인합니다. 만약 있다면 그대로 해당 엔티티를 반환하고 없다면 db에서 실제로 조회 후에 1차 캐시에 저장 후 해당 결과값을 반환합니다.
플로우를 간단히 도식화해보면 위와 같습니다. 요청이 오면 1차 캐시에서 요청과 일치하는 엔티티가 있는지 확인합니다. 만약 있다면 그대로 해당 엔티티를 반환하고 없다면 db에서 실제로 조회 후에 1차 캐시에 저장 후 해당 결과값을 반환합니다.
예제
간단한 예제를 통해 1차 캐시가 잘 동작하는지 확인해보겠습니다.
테스트에 활용된 설정 정보는 다음과 같습니다.
build.gradle
1
2
3
4
5
6
7
8
9
10
dependencies {
implementation 'org.springframework.boot:spring-boot-starter-data-jpa'
implementation 'org.springframework.boot:spring-boot-starter-web'
implementation 'com.github.gavlyukovskiy:p6spy-spring-boot-starter:1.7.1'
compileOnly 'org.projectlombok:lombok'
runtimeOnly 'com.h2database:h2'
annotationProcessor 'org.projectlombok:lombok'
testImplementation 'org.springframework.boot:spring-boot-starter-test'
}
application.yml
1
2
3
4
5
6
7
8
9
10
spring:
datasource:
driver-class-name: org.h2.Driver
url: jdbc:h2:../test
username: sa
password:
jpa:
database-platform: org.hibernate.dialect.H2Dialect
hibernate:
ddl-auto: create-drop
코드는 다음과 같습니다.
TestModel.java
1
2
3
4
5
6
7
8
9
10
11
12
13
@Entity
@Data
@NoArgsConstructor
@Table(name = "test_model")
public class TestModel {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
Long id;
String keyword;
}
TestService.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
@Service
public class TestService {
@Autowired
TestRepository testRepository;
@Transactional
public void insertDummyData() {
var r = Arrays.asList("banana", "monkey", "apple", "bear");
Random rand = new Random();
for (var a = 0; a < 10; a ++) {
TestModel testModel = new TestModel();
testModel.setKeyword(r.get(rand.nextInt(r.size())));
testRepository.save(testModel);
}
}
}
Test.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
@Test
@Transactional
void test() {
testService.insertDummyData();
var listAll = testRepo.findAll();
Assert.notNull(listAll, "ENTITY LIST SHOULD NOT BE NULL");
for (var i = 1L; i <= 10L; i ++) {
var entity = testRepo.findById(i).orElse(null);
Assert.notNull(entity, "ENTITY SHOULD NOT BE NULL");
}
var entity = testRepo.findById(12L).orElse(null);
Assert.isNull(entity, "ENTITY SHOULD BE NULL");
}
10개의 엔티티를 저장하고 testRepo.findAll() 로 모든 엔티티를 불러와 1차캐시에 저장하였습니다. 만약 1차 캐시가 없다면 반복문 부분에서 1L부터 10L까지 10번 조회하는 쿼리가 날라갈 것입니다.
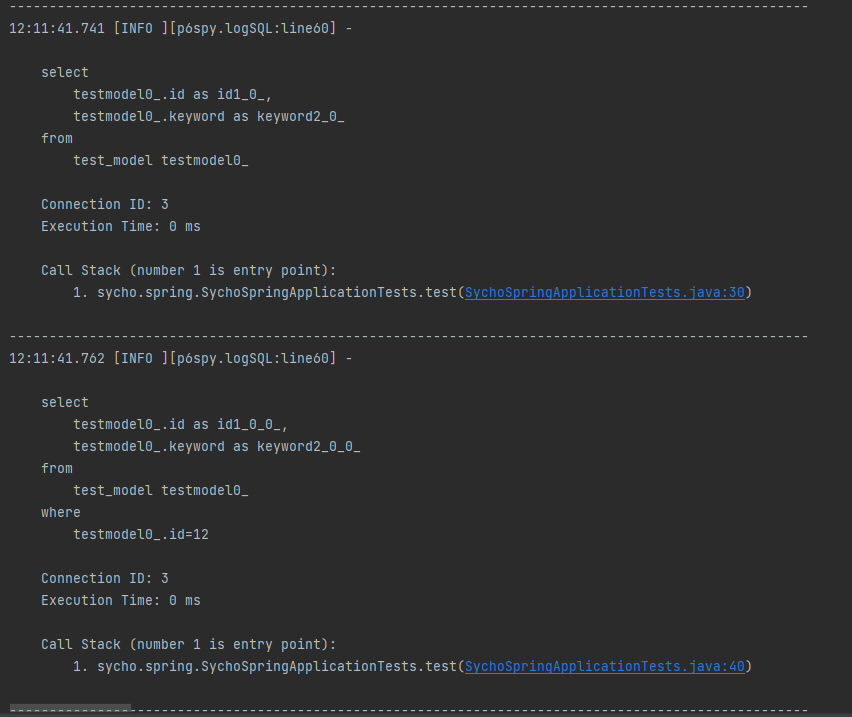 하지만 위와 같이
하지만 위와 같이 select * from test_model절 이후에 반복문 내부의 findById() 로 생성되고 실행되어야 할 쿼리는 생성되지 않고 바로 testRepo.findById(12L).orElse(null)의 쿼리인 select * from test_model where id=12절이 실행된것을 확인할 수 있습니다.
이로써 findAll() 로 조회된 id 1~10까지의 엔티티는 1차캐시에서 바로 반환되었고 1차캐시에 존재하지 않는 id 12의 경우 쿼리가 생성되어 실제 db에서 조회하여 결과값을 반환한 것을 확인할 수 있습니다.
2차 캐시
1차 캐시가 트랜잭션 단위의 캐시라면 2차 캐시는 어플리케이션 단위의 캐시입니다. 따라서 어플리케이션을 시작하고 종료할 때까지 캐시가 유지됩니다. 2차 캐시는 다음과 같은 특징을 가지고 있습니다.
- 동시성을 극대화하기 위해 엔티티를 직접 반환하지 않고 복사본(dto)을 만들어 반환한다.
- 2차 캐시는 영속성 유닛 범위의 캐시다.
- 2차 캐시는 데이터베이스의 기본키를 기준으로 캐싱하지만 영속성 컨텍스트가 다르면 객체 동일성 (a == b)를 보장하지 않는다.
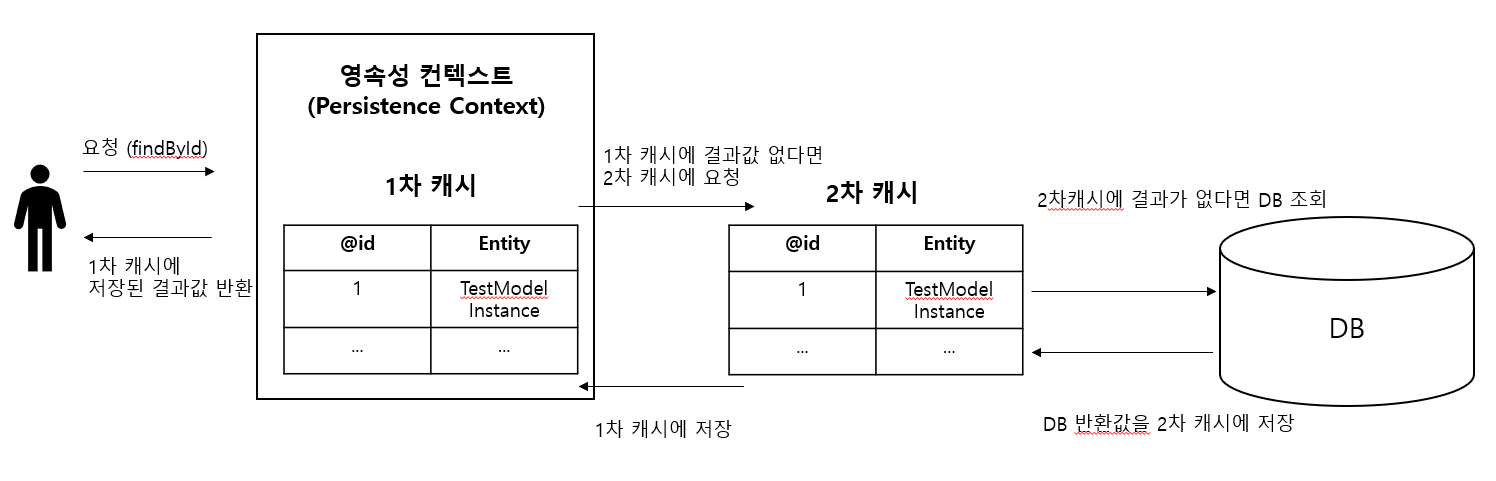
2차 캐시의 플로우를 도식화 하였습니다. 1차 캐시와 DB 사이에 2차 캐시 레이어가 추가되었습니다. 1차, 2차 캐시에 모두 원하는 요청값이 없는 경우 DB에서 조회후 2차캐시, 1차캐시에 순차적으로 저장 후 결과값을 반환합니다.
Region Factory
하이버네이트 2차 캐시는 실제로 어떤 캐시 프로바이더가 사용되는지 알 수 없게 설계되었습니다. 하이버네이트는 org.hibernate.cache.spi.RegionFactory 인터페이스를 구현한 구현체만을 필요로 합니다.
위 인터페이스는 실제 캐시 프로바이더와 관련된 모든 정보를 캡슐화합니다. 또한 기본적으로 하이버네이트와 캐시 프로바이더 사이의 브릿지 역할을 합니다.
아래 예제에서는 Ehcache를 사용합니다. RegionFactory 인터페이스가 구현되어있는 어떤 구현체를 사용해도 문제 없습니다.
예제
2차 캐시를 실제로 적용해보겠습니다.
일단 gradle 디펜던시에 ehcache를 추가합니다.
1
implementation 'org.hibernate:hibernate-ehcache:5.6.3.Final'
그 후 application.yml 파일에 프로퍼티를 추가합니다.
1
2
3
4
5
6
7
8
9
10
11
12
spring:
jpa:
properties:
javax:
persistence:
sharedCache:
mode: ALL
hibernate:
cache:
use_second_level_cache: true
region:
factory_class: org.hibernate.cache.ehcache.EhCacheRegionFactory
use_second_level_cache 프로퍼티를 통해 2차캐시를 활성화하고 factory_class 프로퍼티를 통해 EhCacheRegionFactory를 2차 캐시 프로바이더로 선택합니다. sharedCache.mode 프로퍼티를 통해 캐싱할 엔티티의 범위를 지정할 수 있는데 선택 가능한 모드는 다음과 같습니다.
ALL: 모든 엔티티 및 엔티티 관련 상태와 데이터가 캐시됩니다.
DISABLE_SELECTIVE: @Cacheable 어노테이션에 false 라고 명시된 엔티티를 제외한 모든 엔티티에 대해 캐싱을 사용할 수 있습니다.
ENABLE_SELECTIVE: @Cacheable 어노테이션에 true 라고 명시된 모든 엔티티에 대해 캐싱을 사용할 수 있습니다.
NONE: 영속성 유닛에서 캐싱을 사용할 수 없습니다.
UNSPECIFIED: 캐싱 동작이 정의되지 않았습니다. 프로바이더별 기본값이 적용될 수 있습니다.
더 자세한 정보는 이곳을 참조하세요.
다음으로 캐싱할 엔티티에 캐시 기능을 사용하겠다고 어노테이션을 추가해줘야 합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Entity
@Data
@NoArgsConstructor
@Table(name = "test_model")
@Cacheable
@org.hibernate.annotations.Cache(usage = CacheConcurrencyStrategy.NONSTRICT_READ_WRITE)
public class TestModel {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
Long id;
String keyword;
}
@Cacheable 어노테이션으로 이 엔티티가 캐싱될수 있음을 명시하였습니다. @Cache 어노테이션와 usage() 속성을 통해 캐시 전략을 명시하였습니다. 사용할수 있는 전략은 다음과 같습니다.
NONE: 전략이 없습니다.
READ_ONLY: 읽기 전용입니다. 불변값에 적합합니다.
NONSTRICT_READ_WRITE: 엄격하지 않은 읽기/쓰기 전략입니다. 동시성 접근을 고려하지 않고 캐싱합니다. 수정이 자주 일어나지 않는 엔티티에 적합합니다.
READ_WRITE: 엄격한 읽기/쓰기 전략입니다. 동시 접근을 고려하고 개발해야 합니다.
TRANSACTIONAL: JTA 환경에서 사용되며 hibernate.transaction.manager_lookup_class 프로퍼티를 명시해야 합니다.
이곳 에서 더 자세한 정보를 확인해보세요.
설정이 모두 끝났습니다. 테스트에 사용될 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
@RestController
public class CacheTestController {
@Autowired
TestRepository testRepository;
@Autowired
TestService testService;
@Autowired
SessionFactory sessionFactory;
@GetMapping("/insert")
public ResponseEntity<?> insert() {
var r = Arrays.asList("banana", "monkey", "apple", "bear");
Random rand = new Random();
for (var a = 0; a < 10; a ++) {
TestModel testModel = new TestModel();
testModel.setKeyword(r.get(rand.nextInt(r.size())));
testRepository.save(testModel);
}
return ResponseEntity.ok("SUCCESS");
}
@GetMapping("/getById")
public ResponseEntity<?> getById(@RequestParam Long id) {
sessionFactory.getStatistics().setStatisticsEnabled(true);
System.out.println("=========================");
System.out.println("find entity start");
var e = testRepository.findById(id).orElse(null);
System.out.println("second level cache hit count: " + sessionFactory.getStatistics().getSecondLevelCacheHitCount());
System.out.println("second level cache miss count: " + sessionFactory.getStatistics().getSecondLevelCacheMissCount());
System.out.println("second level cache put count: " + sessionFactory.getStatistics().getSecondLevelCachePutCount());
System.out.println("find entity end");
return ResponseEntity.ok(e);
}
}
편의를 위해 h2 메모리 db를 사용하였습니다. 테스트 시나리오는 어플리케이션 실행후 insert() 메소드를 통해 10개의 엔티티를 저장합니다. 그 후 getById(id) 메소드를 통해 id가 1인 엔티티를 두번 조회후 id가 2인 엔티티를 두번 조회해 보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
10:11:42.982 [INFO ][p6spy.logSQL:line60] -
=========================
find entity start
10:12:03.542 [INFO ][p6spy.logSQL:line60] -
select
testmodel0_.id as id1_0_0_,
testmodel0_.keyword as keyword2_0_0_
from
test_model testmodel0_
where
testmodel0_.id=1
Connection ID: 4
Execution Time: 0 ms
Call Stack (number 1 is entry point):
1. sycho.spring.controller.CacheTestController.getById(CacheTestController.java:50)
----------------------------------------------------------------------------------------------------
10:12:03.560 [INFO ][p6spy.logSQL:line60] -
second level cache hit count: 0
second level cache miss count: 1
second level cache put count: 1
find entity end
=========================
find entity start
10:12:05.356 [INFO ][p6spy.logSQL:line60] -
second level cache hit count: 1
second level cache miss count: 1
second level cache put count: 1
find entity end
=========================
find entity start
10:12:06.855 [INFO ][p6spy.logSQL:line60] -
select
testmodel0_.id as id1_0_0_,
testmodel0_.keyword as keyword2_0_0_
from
test_model testmodel0_
where
testmodel0_.id=2
Connection ID: 6
Execution Time: 0 ms
Call Stack (number 1 is entry point):
1. sycho.spring.controller.CacheTestController.getById(CacheTestController.java:50)
----------------------------------------------------------------------------------------------------
10:12:06.858 [INFO ][p6spy.logSQL:line60] -
second level cache hit count: 1
second level cache miss count: 2
second level cache put count: 2
find entity end
=========================
find entity start
10:12:07.940 [INFO ][p6spy.logSQL:line60] -
second level cache hit count: 2
second level cache miss count: 2
second level cache put count: 2
find entity end
테스트 결과는 위와 같습니다. 최초 id가 1인 엔티티를 조회할때는 2차 캐시에 데이터가 존재하지 않기 때문에 실제 쿼리가 날라가고 miss count와 put count 가 1이 되었습니다. 그 후 다시한번 id가 1인 엔티티를 조회할 때는 2차 캐시에 엔티티가 존재하기 때문에 쿼리가 날라가지 않고 hit count가 1이 되었습니다.
id를 2로하여 조회해봐도 1로 조회할때와 마찬가지로 최초 조회때는 실제 쿼리가 날라가고 2번째 조회때는 캐시된 엔티티를 반환하는 것을 확인할 수 있습니다.
분산환경에서의 2차 캐시
하지만 요즘에는 단일환경에서 어플리케이션을 잘 운영하지 않습니다. AWS를 사용한다고 가정하면 오토 스케일링 그룹의 EC2에 동일한 어플리케이션을 구동하여 분산환경에서 자유롭게 스케일링 in / out 할 수 있는 형태로 서버를 구성합니다.
메모리 db가 어플리케이션 단위로 동작하는 경우 최종 db에 커밋시에 문제가 생길수 있습니다. db lock 에 의해 문제가 생기지 않을 수 있지만 뒤에 처리하는 비즈니스 로직에서 문제가 발생할 수 있습니다. 따라서 기본적으로 별도의 서버에 메모리 db 을 구축하여 사용할 수 있습니다. 물론 이때도 올바른 캐시 전략을 지정하는것은 중요합니다.
단일 노드 환경에서는 READ_WRITE, TRANSACTIONL 전략을 사용할 수 있습니다. 그러나 분산 노드 환경에서는 db lock 에 의존할 수 없으므로 NONSTRICT_READ_WRITE 전략을 사용해야 합니다. 어떤 곳에서는 일관성을 위해 (quorum 알고리즘)[https://en.wikipedia.org/wiki/Quorum_(distributed_computing)] 을 사용하는 메모리 db 에서는 READ_WRITE 을 사용해도 된다고 하네요.
개인적으로 외부로 메모리 db를 빼고 _WRITE 전략을 사용하는것은 세세한 설정이 필요하고 유지보수에 더 큰 리소스가 들어갈 수 있기 때문에 선호하지 않는 편입니다. 그렇다 하더라도 2차캐시 자체는 충분히 매력적인 기능이라 생각합니다.